Traduction, sous-titres, résumés et transcriptions en temps réel par IA
Synthèse vocale
Donnez vie au texte traduit grâce à un son naturel en temps réel. Wordly Text-to-Speech convertit le texte traduit en une sortie vocale de haute qualité afin que les participants puissent écouter dans leur langue préférée, ce qui est idéal pour les réunions et les événements.
Pourquoi choisir Wordly Text-to-Speech
La synthèse vocale offre aux participants bien plus que des mots sur un écran. Il améliore la compréhension, accroît l'accessibilité et aide le public du monde entier à rester engagé en lui permettant d'entendre le contenu comme prévu. Associé à la traduction en direct et au sous-titrage de Wordly, il crée une expérience plus riche et plus flexible pour chaque participant.
- Des voix naturelles semblables à des voix humaines utilisant la technologie moderne de synthèse vocale (TTS) pour une intonation expressive et une prononciation claire
- Sortie audio rapide à faible latence optimisée pour les événements en direct afin que le son traduit reste aligné avec le haut-parleur
- Support multilingue qui permet aux participants d'écouter des traductions dans des dizaines de langues
- Assistance en matière d'accessibilité pour vous aider à répondre aux exigences en matière d'accès et d'inclusion linguistiques
- Entièrement intégré au Plateforme Wordly pour une expérience unifiée pour les participants grâce aux sous-titres, à l'audio et aux transcriptions
Comment fonctionne la synthèse vocale de Wordly
Wordly Text-to-Speech est construit sur la même plate-forme que celle qui alimente notre traduction en direct et fonctionnalités de sous-titrage. Chaque étape du processus est conçue pour fournir rapidement un son précis, même lorsque les intervenants changent de rythme ou de sujet. Le résultat est un son naturel diffusé dans la langue préférée de chaque participant.
Étape 1 : Wordly capture le son du présentateur
Étape 2 : L'audio est transcrit en texte à l'aide de notre modèle de reconnaissance vocale
Étape 3 : Le texte est traduit dans la langue sélectionnée par le participant à l'aide de la traduction automatique et des modèles LLM
Étape 4 : Le texte traduit est converti en streaming audio naturel et diffusé sur l'appareil du participant en temps réel
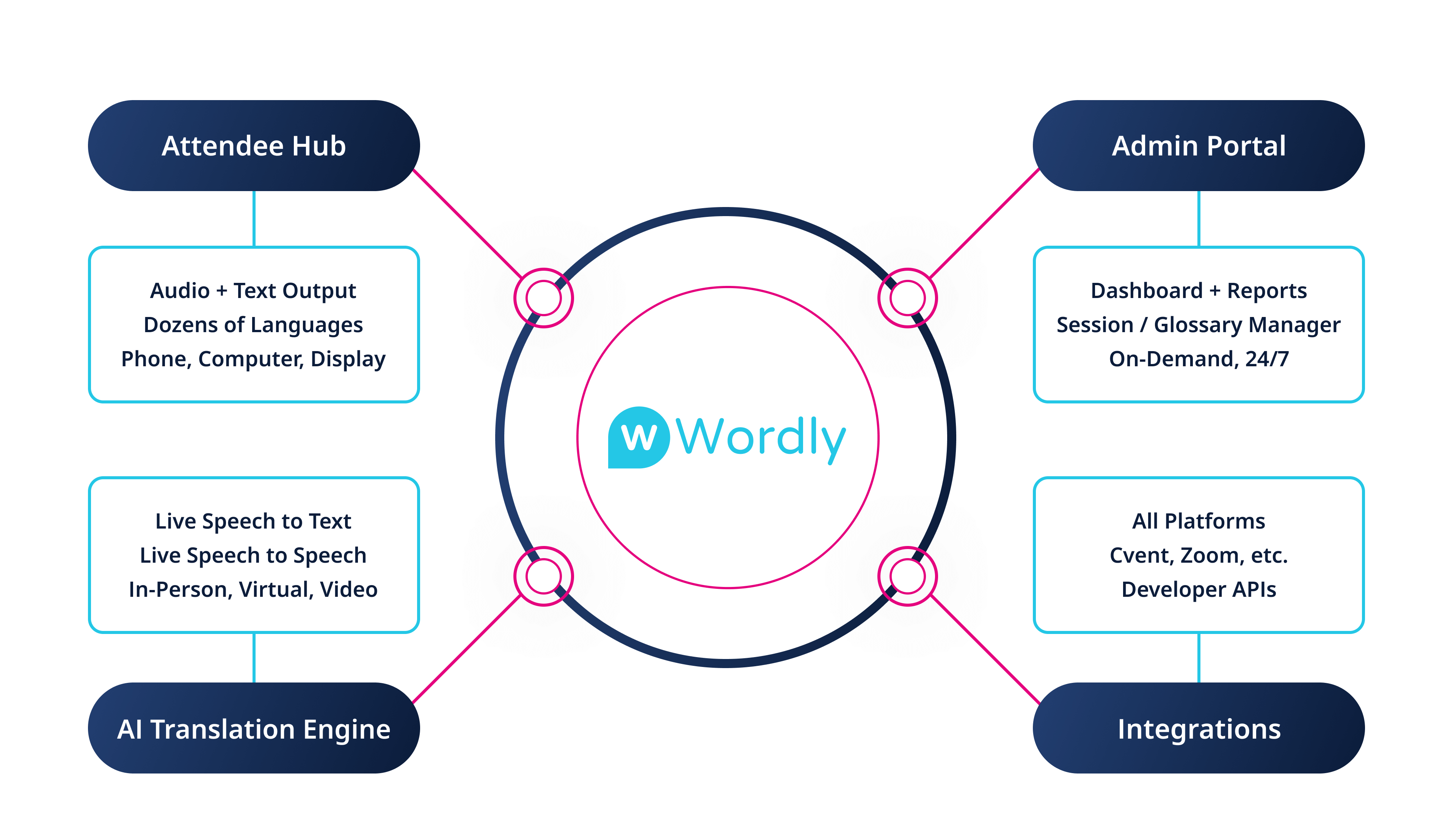
Fonctionnalités de synthèse vocale de Wordly
La synthèse vocale est conçue pour prendre en charge l'ensemble des formats de réunions et d'événements. Les participants peuvent contrôler la façon dont ils souhaitent écouter, tandis que les organisateurs assurent une expérience cohérente et fiable sur tous les appareils et environnements.
- Streaming audio en temps réel qui reste synchronisé avec l'événement
- Plusieurs options vocales, y compris les accents régionaux, le cas échéant
- Sélection de la langue par participant afin que chaque auditeur choisisse sa propre langue de lecture
- Audio combiné avec sous-titrage en direct et des transcriptions pour un maximum d'accessibilité et d'engagement
- Conçu pour les réunions et les événements en direct afin que les participants puissent écouter sur leurs propres appareils sans matériel supplémentaire
Cas d'utilisation de la synthèse vocale dans Wordly
La synthèse vocale améliore la compréhension, permet des expériences accessibles et accroît la valeur du contenu longtemps après la fin des sessions en direct. Que les participants participent en temps réel ou regardent des enregistrements, ils peuvent facilement écouter dans la langue de leur choix.
- Conférences en direct et événements hybrides où les participants internationaux ont besoin d'entendre des conférenciers dans leur langue préférée
- Webinaires et assemblées publiques pour améliorer la compréhension et l'engagement au sein des organisations mondiales
- Lecture de vidéos et contenus enregistrés pour lesquels vous souhaitez générer des pistes audio localisées pour un visionnage à la demande
- Des flux de travail d'accessibilité qui fournissent des traductions orales aux participants malvoyants et à l'assistance accès linguistique lignes directrices
Détails techniques et performances de synthèse vocale
Wordly Text-to-Speech est conçu pour offrir des performances constantes à toutes les échelles. Qu'une session compte une poignée ou des milliers de participants, Wordly est conçu pour fournir un son rapide et clair et fournir aux hôtes et aux participants des commandes intuitives pour gérer les préférences de lecture.
- Latence et optimisation : Wordly améliore continuellement la vitesse de diffusion audio pour que la lecture reste étroitement alignée sur celle du haut-parleur
- Qualité : Utilise des modèles de synthèse vocale et de traduction de pointe pour préserver le contexte, les expressions idiomatiques et le rythme naturel
- Commandes : Les présentateurs et les participants peuvent activer ou désactiver la synthèse vocale dans leurs paramètres
Questions fréquemment posées sur les transcriptions vocales
Qu'est-ce que la synthèse vocale ?
La synthèse vocale est le processus de conversion de texte écrit en audio parlé à l'aide de voix IA. Avec Wordly, le texte traduit est transformé en audio naturel en temps réel afin que les participants puissent écouter le contenu de la réunion dans leur langue préférée. Il prend en charge les événements en direct, les webinaires et le contenu enregistré et fonctionne parfaitement avec les sous-titres, les transcriptions et les traductions.
Quelles sont les langues prises en charge par Wordly Text-to-Speech ?
Wordly prend en charge l'audio TTS dans des dizaines de langues. Les participants peuvent choisir leur langue d'écoute préférée directement depuis l'interface, et les organisateurs peuvent activer autant de langues de sortie que nécessaire pour une session.
Quel est le délai entre le haut-parleur et le son de synthèse vocale ?
Wordly est optimisé pour les événements en temps réel et fournit un son à très faible latence. La plupart des participants ne connaissent qu'un léger retard, similaire à ce qu'ils entendraient avec une interprétation simultanée.
Puis-je utiliser la synthèse vocale lors d'événements en présentiel ?
Oui. Les participants aux conférences en personne et aux réunions hybrides peuvent écouter le son TTS sur leurs propres appareils à l'aide d'un code QR ou d'un lien vers l'événement. Il n'est donc plus nécessaire de recourir à des casques ou à des équipements audio spécialisés.
La synthèse vocale peut-elle être combinée à des sous-titres et à des transcriptions ?
Oui Les participants peuvent écouter l'audio TTS tout en lisant les sous-titres. Après l'événement, les organisateurs peuvent télécharger les transcriptions et le texte traduit pour les résumés, les notes et les flux de travail de contenu à la demande.
Commencez avec Wordly Text-to-Speech
La synthèse vocale permet à chaque participant de suivre le cours en fournissant un son naturel en temps réel dans la langue de son choix. Avec Wordly, vous pouvez proposer des fichiers audio traduits de haute qualité ainsi que des sous-titres et des transcriptions lors de toute réunion ou événement.
Nous contacter pour savoir comment Wordly Text-to-Speech peut vous aider lors de votre prochaine conférence, webinaire ou session de formation.

.avif)
.avif)
.png)
.png)
%20(1)%201.png)
.png)